Author:
Pavithra P, Priya N, Naveenkumar EPublished in
Journal of Science Technology and Research( Volume , Issue )
ABSTRACT:
Speech Emotion Recognition (SER) is a key component in modern human-computer interaction systems. It enables machines to understand human emotions through speech, improving the quality of communication and user experience. This project focuses on developing an automatic SER model using deep learning, specifically Recurrent Neural Network Based Speech. RNNs are effective for processing sequential data and reducing overfitting by randomly omitting neurons in hidden layers. The proposed system is trained to detect four emotional states: happy, sad, angry, and intoxicated. It integrates speech enhancement to eliminate background noise, improving recognition accuracy. The goal is to build a system that offers improved emotion-based responses, suitable for personal assistant applications. Simulation results show increased accuracy, reduced error rate, and lower time complexity when using the RNN model. Recurrent Neural Network Based Speech solution can be applied in lie detectors, user mood analysis, and emotion-aware interfaces, offering more appropriate and intelligent interactions between humans and smart systems.
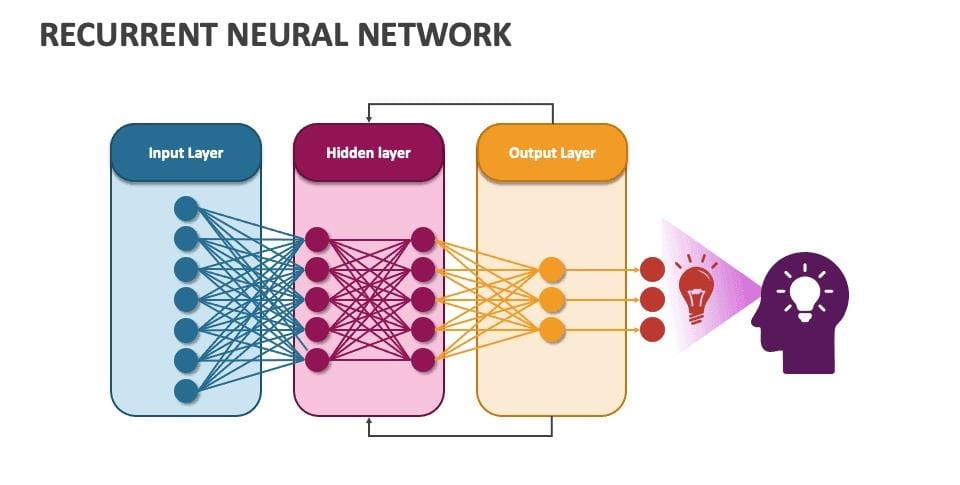
Recurrent Neural Network Based Speech:
Speech is a natural medium for human communication, and emotions make it expressive and meaningful. Recognizing emotional states in speech is vital for intelligent systems that aim to respond empathetically to users. This study explores Speech Emotion Recognition (SER) using Recurrent Neural Networks (RNN), a deep learning method effective for sequential data. Emotions like happiness, sadness, anger, and intoxication significantly influence pitch, tone, and frequency in speech. Traditional systems lack accuracy and struggle with real-world noise. To address these issues, our approach incorporates automatic speech enhancement, improving emotional clarity. The RNN-based model captures low-level audio features without needing manual tuning. It also supports better generalization by omitting certain neurons during training, avoiding overfitting. SER plays a critical role in personal assistants, lie detection, and psychological analysis. By understanding emotional cues, machines can interact more naturally, providing timely feedback and improving the overall experience. This makes SER an essential part of modern intelligent systems.